



I. Introduction▲
I-A. Définition▲
Pour tout bon informaticien, le terme « partitionnement » n'est pas inconnu. Cependant, bien que le partitionnement d'un disque dur soit devenu une banalité, l'utilisation du partitionnement en base de données reste encore rare.
Faisons tout d'abord un rappel sur le partitionnement d'un disque dur. L'intérêt de créer différentes partitions est de pouvoir organiser les données : des partitions sont réservées aux fichiers des systèmes d'exploitation installés et d'autres pour les données personnelles (photos, téléchargements…).
Dans cet article, nous allons nous intéresser au partitionnement dans le domaine des bases de données, et plus exactement au partitionnement de tables. Le but est, comme pour les disques durs, d'organiser les données. Néanmoins, nous n'allons pas utiliser cette organisation pour simplifier nos requêtes, mais bien pour en améliorer les performances !
I-B. Les types de partitionnement▲
Deux grands types de partitionnement sont utilisés pour partitionner une table :
- partitionnement horizontal : les enregistrements (= lignes) d'une table sont répartis dans plusieurs partitions. Il est nécessaire de définir une condition de partitionnement, qui servira de règle pour déterminer dans quelle partition ira chaque enregistrement.
Exemple : nous disposons d'une table Amis et nous choisissons de la partitionner en
deux partitions :
- Les amis dont la première lettre du prénom est comprise entre A et M,
- Les amis dont la première lettre du prénom est comprise entre N et Z.
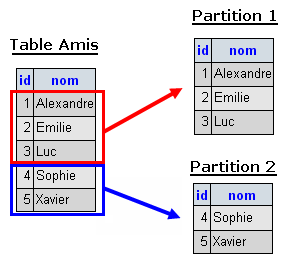
Pour récupérer la liste complète de nos amis, il sera nécessaire de regrouper le contenu de nos deux partitions. Pour ce faire, une simple opération d'union d'ensembles suffit ;
- partitionnement vertical : les colonnes d'une table sont réparties dans plusieurs partitions. Cela peut être pratique pour écarter des données fréquemment utilisées d'autres auxquelles l'accès est plus rare.
Exemple : nous disposons d'une table Amis contenant les prénom et photo de chacun de nos amis. Les photos prenant de la place et étant rarement accédées, nous décidons de les écarter des autres données.
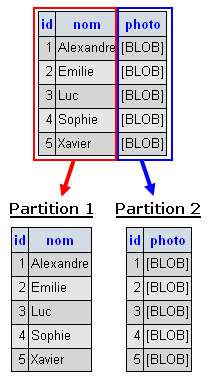
Comme vous pouvez le remarquer, les deux partitions contiennent l'identifiant des amis. Cela est nécessaire afin de garder le lien entre les données de chaque enregistrement. Ainsi, pour récupérer toutes les informations des amis, il suffit de faire une jointure entre les deux partitions.
Nous connaissons maintenant les deux types de partitionnement. Il est bien sûr possible d'utiliser un partitionnement vertical et un partitionnement horizontal sur une même table, ainsi que de partitionner sur plusieurs niveaux, c'est-à-dire définir des partitions de partitions.
I-C. Les avantages du partitionnement▲
Le partitionnement apporte plusieurs avantages à un administrateur de base de données. Voici les principaux intérêts du partitionnement :
- pouvoir créer des tables plus grandes que la taille permise par un disque dur ou par une partition du système de fichiers : il est tout à fait possible de stocker des partitions à des endroits (partitions, disques, serveurs…) différents ;
- pouvoir supprimer très rapidement des données qui ne sont plus utiles et utilisées : si ces données sont placées sur une partition séparée, il suffit de détruire la partition pour supprimer toutes les données ;
- optimiser grandement certaines requêtes : les données étant organisées dans différentes partitions, le SGBD n'accède qu'aux données nécessaires lors des requêtes. Sans partitionnement, tous les enregistrements sont pris en compte.
Enfin, notons que le partitionnement de tables est généralement utilisé avec des bases de données réparties où les données sont placées sur des sites géographiques (éloignés ou proches) différents. Cet article se limite au partitionnement sur site local, mais les principes évoqués sont valides pour le partitionnement distant.
I-D. Notes à propos de MySQL▲
Dans MySQL, le partitionnement n'est géré de manière automatique qu'à partir de la version 5.1. Lors de la rédaction de cet article, MySQL 5.1 est encore en version bêta et par conséquent, il est possible que des bogues subsistent.
De plus, il est important de noter que seules les fonctionnalités de base du partitionnement seront disponibles dans la version finale de MySQL 5.1. Mais il est évident que les versions futures du SGBD apporteront leur lot d'améliorations.
II. Le partitionnement horizontal avec MySQL▲
Commençons par voir le partitionnement horizontal, qui pour rappel, consiste à répartir les enregistrements d'une table dans différentes partitions. Pour déterminer à quelle partition appartient chaque enregistrement, il faut définir un critère de partitionnement.
II-A. Les méthodes de partitionnement de MySQL▲
Actuellement, MySQL propose quatre moyens d'exprimer ce critère et donc quatre types de partitionnement horizontal.
- Partitionnement par intervalles (Range partitioning) : les enregistrements sont répartis en fonction de la valeur d'une colonne, par rapport à un ensemble d'intervalles définissant le domaine d'appartenance de chaque partition.
Exemple : soit la table Employe (id, nom, prenom, service, salaire) et un partitionnement en fonction de la valeur de la colonne salaire. Nous décidons de définir trois partitions :
Partition 1 : salaire < 1500 ;
Partition 2 : 1500 <= salaire < 3000 ;
Partition 3 : salaire >= 3000.
Les enregistrements suivants seront répartis ainsi :
(1, 'Dupond', 'Benard', 'Administratif', 3100) --> Partition 3
(2, 'Smith', 'John', 'Technique', 1400) --> Partition 1
(3, 'Lucaza', 'Sophie', 'RHC', 1800) --> Partition 2- Partitionnement par listes (List partitioning) : même principe que le partitionnement par intervalles, mais la partition d'un enregistrement est déterminée à partir de listes de valeurs.
Exemple : soit la table Employe (id, nom, prenom, service, salaire) et un partitionnement en fonction de la valeur de la colonne service. Nous décidons de définir deux partitions :
Partition 1 : service = { 'Administratif', 'RHC' }
Partition 2 : service = { 'Technique', 'Informatique' }
Les enregistrements suivants seront répartis ainsi :
(1, 'Dupond', 'Benard', 'Administratif', 3100) --> Partition 1
(2, 'Smith', 'John', 'Technique', 1400) --> Partition 2
(3, 'Lucaza', 'Sophie', 'RHC', 1800) --> Partition 1Actuellement, MySQL 5.1.11 ne supporte que les listes de valeurs de nombres entiers. Pour implémenter notre exemple, il sera donc nécessaire de créer une table « Service » et assigner un identifiant numérique à chaque service.
- Partitionnement par hachage (Hash partitioning) : la partition à laquelle appartient un enregistrement est déterminée à partir de la valeur de retour d'une fonction définie par l'utilisateur. Cette fonction de hachage doit donc opérer un traitement sur la valeur d'une ou plusieurs colonnes des enregistrements.
- Partitionnement par clé (Key partitioning) : cette méthode de partitionnement est similaire au partitionnement par hachage, à l'exception que la fonction de hachage est fournie par le serveur MySQL.
II-B. Mise en place de la base de tests▲
Tous les exemples qui vont suivre pour le partitionnement horizontal ont été réalisés sur une même structure de base de données. Cela va nous permettre de comparer les inconvénients et avantages de chaque type de partitionnement.
Avant de commencer, mettons-nous en situation. Imaginons que l'entreprise pour laquelle vous travaillez enregistre toutes les transactions (peu importe leur type) qu'elle réalise avec ses clients et ses partenaires. Voici le code MySQL qui a été utilisé pour créer la table principale des transactions.
2.
3.
4.
5.
6.
7.
CREATE TABLE transac
(
id INT UNSIGNED PRIMARY KEY,
montant INT UNSIGNED NOT NULL,
jour DATE NOT NULL,
codePays ENUM('FR', 'BE', 'UK', 'US', 'CA', 'JP') NOT NULL
);
Chaque transaction est identifiée par un numéro unique (id). De plus, pour chaque transaction, nous stockons le montant, la date ainsi que le code du pays dans lequel la transaction a eu lieu.
Le nombre de transactions enregistrées se compte en millions, et au fil des années, les performances des requêtes exécutées sur cette table se sont dégradées. Votre patron vous a demandé de trouver une solution et des collègues vous ont même suggéré d'abandonner MySQL pour « un meilleur SGBD ». Bien évidemment, vous ne comptez pas remplacer votre dauphin fétiche si facilement. Vous décidez donc de partitionner cette table de transactions et analyser si la vitesse d'exécution des requêtes fréquentes est améliorée.
Dans la suite de l'article, nous allons analyser plusieurs méthodes pour optimiser les requêtes. Mais afin de réaliser nos tests dans de bonnes conditions, nous allons avoir besoin de remplir notre table de transactions. Nous n'allons bien sûr pas insérer plusieurs millions d'enregistrements à la main. La procédure suivante permettra de générer et d'ajouter autant d'enregistrements que nous le désirerons :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
DELIMITER //
CREATE PROCEDURE remplir_transaction(nbTransacs INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE nbAlea DOUBLE;
DECLARE _jour DATE;
DECLARE _montant INT UNSIGNED;
DECLARE _codePays TINYINT UNSIGNED;
WHILE i <= nbTransacs DO
SET nbAlea = RAND();
SET _jour = ADDDATE('1996-01-01', FLOOR(nbAlea * 4015));
SET _montant = FLOOR(1 + (nbAlea * 9999));
SET nbAlea = RAND();
SET _codePays = FLOOR(1 + (nbAlea * 6));
INSERT INTO transac (id, montant, jour, codePays) VALUES (i, _montant, _jour, _codePays);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
Vous pouvez exécuter le code précédent, mais ne lancez pas encore la procédure. Nous le ferons en temps voulu. Avant tout, il nous faut créer nos partitions.
II-C. Comment réussir son partitionnement horizontal ?▲
Nous savons qu'en partitionnant une table, il est possible d'améliorer les performances des requêtes puisque le nombre d'enregistrements analysés peut être considérablement réduit. Mais encore faut-il réaliser un bon partitionnement horizontal !
La première question qui doit vous venir à l'esprit est : « Qu'est-ce qu'un bon partitionnement ? » La réponse est simple : un bon partitionnement est un partitionnement adapté aux requêtes fréquentes et lourdes en exécution.
Le partitionnement n'est pas miraculeux. Il est impensable de croire que toute requête faite sur une table partitionnée sera optimisée. Certaines requêtes seront plus lentes que sans partitionnement, alors que d'autres s'exécuteront peut-être cinq fois plus rapidement ! C'est la raison pour laquelle, avant de commencer tout partitionnement, il est nécessaire de lister les requêtes qui sont ou seront régulièrement exécutées. En optimisant celles-ci, il sera probablement possible de réduire la charge du serveur, même si certaines requêtes moins fréquentes mettront un peu plus de temps pour s'exécuter.
Après avoir listé les requêtes à optimiser, il faut les analyser. Le but est de déterminer les données qui sont accédées indépendamment et ainsi répartir ces données dans des partitions différentes. Par exemple, si des enregistrements sont souvent accédés par mois (statistiques mensuelles), il peut être judicieux de créer une partition pour chaque mois enregistré.
Dans les exemples qui suivent, nous allons voir des partitionnements efficaces et d'autres complètement inutiles et donc à éviter.
II-D. Partitionnement par intervalles (Range partitioning)▲
Revenons à notre table de transactions et à nos requêtes à optimiser. En vous renseignant sur les requêtes fréquentes et gourmandes, vous apprenez que les employés de l'entreprise utilisent une application spécifique pour gérer les transactions. Cette application permet notamment de lister les transactions pour chaque mois et année enregistrés ainsi que calculer différentes statistiques sur des périodes données.
Ainsi, les requêtes fréquentes sont de la forme suivante :
2.
3.
SELECT SUM(montant) FROM transac WHERE jour BETWEEN '2003-01-01' AND '2003-03-31';
SELECT * FROM transac WHERE jour BETWEEN '2005-01-01' AND '2005-01-31' LIMIT x, y;
Vous remarquez rapidement que les transactions sont accédées par leur date. Ainsi, vous décidez de répartir les millions de transactions par leur année. Vous choisissez donc un partitionnement par intervalles, où un intervalle de 12 mois est assigné à chaque partition.
Voyons comment mettre en place ce partitionnement. Si ce n'est pas fait, créez la table transac ainsi que la procédure remplir_transaction grâce aux codes donnés précédemment.
Mettons maintenant en place la même table de transactions, mais avec une partition par intervalles.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
CREATE TABLE transac_part
(
id INT UNSIGNED NOT NULL,
montant INT UNSIGNED NOT NULL,
jour DATE NOT NULL,
codePays ENUM('FR', 'BE', 'UK', 'US', 'CA', 'JP') NOT NULL
) PARTITION BY RANGE(YEAR(jour))
(
PARTITION p1 VALUES LESS THAN(1997),
PARTITION p2 VALUES LESS THAN(1998),
PARTITION p3 VALUES LESS THAN(1999),
PARTITION p4 VALUES LESS THAN(2000),
PARTITION p5 VALUES LESS THAN(2001),
PARTITION p6 VALUES LESS THAN(2002),
PARTITION p7 VALUES LESS THAN(2003),
PARTITION p8 VALUES LESS THAN(2004),
PARTITION p9 VALUES LESS THAN(2005),
PARTITION p10 VALUES LESS THAN(2006),
PARTITION p11 VALUES LESS THAN MAXVALUE
);
Vous pouvez remarquer la syntaxe utilisée pour créer les partitions. Tout d'abord nous signalons que nous voulons un partitionnement par intervalles en fonction de l'année de la colonne jour, et cela grâce à PARTITION BY RANGE(YEAR(jour)).
Ensuite, nous définissons chaque partition avec le mot clé PARTITION. Comme vous le voyez, 11 partitions ont été créées. Pour chacune d'entre elles, nous donnons la valeur maximale qui peut prendre l'année de la colonne jour, et cela grâce à l'opérateur LESS THAN(). Ainsi, la partition p1 comportera toutes les transactions où l'année est inférieure à 1997 (exclus). Ensuite, la partition p2 regroupera les transactions de l'année 1997, etc.
L'ordre de définition des partitions a de l'importance : si dans le code précédent, p1 et p2 étaient inversées, p1 serait toujours vide ! En effet, lors du placement d'un enregistrement, MySQL analyse les partitions dans l'ordre dans lequel elles ont été définies et s'arrête dès qu'il a trouvé une partition adaptée. Ainsi, si p1 et p2 étaient inversées, les transactions de 1997 (et inférieures) seraient toujours insérées dans p2 puisque 1997 est plus petit que 1998.
La dernière partition est un peu spéciale. Grâce au mot clé MAXVALUE, nous signalons au serveur MySQL que l'année du champ jour pourra prendre toute valeur inférieure à la valeur maximum autorisée pour un champ de type DATE. Ainsi, si notre table n'est pas modifiée en 2007, les transactions de cette année seront placées dans la partition p11.
Si nous avions mis LESS THAN (2007) au lieu de LESS THAN MAXVALUE, l'insertion d'une transaction datée de 2007 aurait provoqué une erreur !
Dès que vous avez créé les deux tables de transactions, exécutez la procédure de remplissage. Les tests qui suivent ont été réalisés avec 10 millions d'enregistrements. Cependant, la génération et l'insertion de ceux-ci peuvent prendre plusieurs dizaines de minutes. Vous pouvez diminuer ce nombre d'enregistrements si vous le souhaitez, grâce au paramètre d'entrée de la procédure. Mais gardez à l'esprit que plus il y a d'enregistrements, plus les tests de performance seront pertinents.
2.
3.
4.
5.
mysql> CALL remplir_transaction(10000000);
Query OK, 1 row affected (10 min 41.63 sec)
mysql> INSERT INTO transac_part SELECT * FROM transac;
Query OK, 10000000 rows affected (1 min 32.96 sec)
Si tout s'est bien passé, nos deux tables sont maintenant remplies avec les mêmes enregistrements. Nous pouvons donc commencer nos tests de comparaison.
Analysons tout d'abord le temps d'exécution d'une requête permettant de calculer le montant total et le montant moyen des transactions de l'année 1998.
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE jour BETWEEN '1998-01-01' AND '1998-12-31';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 2064947969 | 2275.0362 |
+--------------+--------------+
1 row in set (22.59 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE jour BETWEEN '1998-01-01' AND '1998-12-31';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 2064947969 | 2275.0362 |
+--------------+--------------+
1 row in set (2.83 sec)
Cela commence plutôt bien ! Le gain réalisé est de 19,76 secondes, soit une optimisation de 87 %. Je vous laisse faire le calcul si des requêtes similaires sont exécutées des centaines de fois par jour.
Comment expliquer ce gain ? C'est très simple. Dans le premier cas, sans partitionnement, tous les enregistrements de table sont analysés par le SGBD. Dans l'autre, avec partitionnement, le SGBD sait qu'il n'a besoin que d'analyser la partition p3, qui contient tous les enregistrements de 1998.
Pour nous assurer des partitions scannées pour une requête, MySQL a introduit la commande EXPLAIN PARTITIONS. Voici ce qu'elle retourne pour la requête précédente :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
mysql> EXPLAIN PARTITIONS SELECT SUM(montant), AVG(montant) FROM transac_part
-> WHERE jour BETWEEN '1998-01-01' AND '1998-12-31'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: transac_part
partitions: p3
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 907655
Extra: Using where
1 row in set (0.00 sec)
Voyons maintenant les performances si nous calculons le montant total et le montant moyen des transactions réalisées de 1996 à 2000.
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE jour BETWEEN '1996-01-01' AND '2000-12-31';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 10354975423 | 2275.8358 |
+--------------+--------------+
1 row in set (21.04 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE jour BETWEEN '1996-01-01' AND '2000-12-31';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 10354975423 | 2275.8358 |
+--------------+--------------+
1 row in set (9.49 sec)
Nous pouvons remarquer que le gain de performances est beaucoup moins important que précédemment. En effet, ici, cinq partitions ont dû être analysées (p1, p2, p3, p4, p5) pour le cas avec partitionnement. Mais le gain reste énorme puisque moins de la moitié des données ont été scannées (chaque partition contient environ le même nombre d'enregistrements, car la procédure crée des enregistrements avec des dates aléatoires).
Jusqu'à présent, nous avons vu que lorsqu'une partition n'a pas besoin d'être scannée, nous obtenons un gain de performance. Mais que se passe-t-il si toutes les partitions sont scannées ? En d'autres termes, nous pouvons nous demander si le partitionnement réduit grandement la vitesse pour les autres requêtes qui ne peuvent pas profiter de cette optimisation. Pour tester cela, calculons le montant total et le montant moyen de toutes les transactions.
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac;
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 49997440867 | 4999.7441 |
+--------------+--------------+
1 row in set (17.15 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part;
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 49997440867 | 4999.7441 |
+--------------+--------------+
1 row in set (24.03 sec)
Comme prévu, cette requête est ralentie par le partitionnement. Cependant, si cette requête est exécutée moins souvent que les autres requêtes que nous avons optimisées, cette perte de performance devient négligeable !
Revenons à notre situation en entreprise. Après avoir réalisé tous ces tests, vous êtes convaincu que ce partitionnement sera fortement bénéfique. Vous décidez donc de le mettre en place. Bien sûr, vous n'avez pas trop envie de recréer une nouvelle table partitionnée puis de copier le contenu de l'ancienne table vers la nouvelle. Rassurez-vous, MySQL a tout prévu pour partitionner une table existante.
La commande suivante permet de partitionner la table initiale des transactions pour la rendre identique à notre table partitionnée sur laquelle nous avons réalisé les précédents tests :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
ALTER TABLE transac PARTITION BY RANGE(YEAR(jour))
(
PARTITION p1 VALUES LESS THAN(1997),
PARTITION p2 VALUES LESS THAN(1998),
PARTITION p3 VALUES LESS THAN(1999),
PARTITION p4 VALUES LESS THAN(2000),
PARTITION p5 VALUES LESS THAN(2001),
PARTITION p6 VALUES LESS THAN(2002),
PARTITION p7 VALUES LESS THAN(2003),
PARTITION p8 VALUES LESS THAN(2004),
PARTITION p9 VALUES LESS THAN(2005),
PARTITION p10 VALUES LESS THAN(2006),
PARTITION p11 VALUES LESS THAN MAXVALUE
)
Query OK, 10000000 rows affected (32.02 sec)
Records: 10000000 Duplicates: 0 Warnings: 0
Après exécution de cette commande, la table sera partitionnée et chaque enregistrement présent aura été placé dans la partition adéquate. Et comme vous le voyez, le partitionnement s'est fait très rapidement.
De même, la commande ALTER TABLE … REORGANIZE est réellement très pratique pour gérer une table partitionnée. Elle permet de fusionner des partitions, décomposer une partition en plusieurs ou encore changer les intervalles. Nous utiliserons cette commande un peu plus tard.
Nous venons de voir l'un des principaux avantages du partitionnement, qui est l'optimisation de requêtes. Mais si vous vous souvenez bien, un autre avantage du partitionnement est de pouvoir se débarrasser rapidement de données devenues inutiles. Imaginons que votre entreprise décide que l'historique des transactions de 1996 peut être supprimé, car les historiques de 10 ans n'intéressent plus les employés. La première méthode pour les supprimer est bien évidemment un simple DELETE FROM :
2.
mysql> DELETE FROM transac WHERE jour BETWEEN '1996-01-01' AND '1996-12-31';
Query OK, 911306 rows affected (5.88 sec)
Mais grâce à notre partitionnement, la méthode la plus rapide est de supprimer directement la partition des transactions de 1996.
2.
mysql> ALTER TABLE transac DROP PARTITION p1;
Query OK, 0 rows affected (0.42 sec)
II-E. Partitionnement par listes (List partitioning)▲
Jusqu'à présent, nous sommes partis de l'hypothèse que les requêtes exécutées régulièrement utilisaient la date comme critère principal de restriction des résultats. Nous avons vu qu'une partition par intervalles se montrait très efficace pour améliorer la vitesse d'exécution de ces requêtes.
Maintenant, imaginons que nos données sur les transactions soient plutôt accédées par emplacement géographique. Par exemple, certains employés sont responsables des transactions réalisées en Europe, d'autres gèrent les transactions en Asie et enfin, les derniers sont responsables des transactions d'Amérique du Nord.
Rappelons-nous tout d'abord comment est stocké le code du pays dans lequel une transaction a eu lieu :
codePays ENUM('FR', 'BE', 'UK', 'US', 'CA', 'JP') NOT NULL
Si nous désirons répartir les données en fonction de l'emplacement géographique, nous pourrions très bien utiliser un partitionnement par intervalles de valeurs entières. En effet, comme vous le savez sûrement, à chaque valeur possible d'un type énuméré est associée une valeur entière. Il serait donc très simple de créer ces partitions :
- Partition pEurope : 1 <= codePays < 4
- Partition pAmeriqueNord : 4 <= codePays < 6
- Partition pAsie : 6 <= codePays
Cependant, si un pays est ajouté dans le type énuméré, il sera nécessaire de réaliser de nombreuses opérations telles qu'une renumérotation pour garder un intervalle valide. Nous allons plutôt utiliser un partitionnement par listes, qui sera bien plus facile à mettre en œuvre et à maintenir à jour.
- Partition pEurope : codePays ∈ { 'FR', 'BE', 'UK' }
- Partition pAmeriqueNord : codePays ∈ { 'US', 'CA' }
- Partition pAsie : codePays ∈ { 'JP' }
Créons maintenant nos partitions avec MySQL. Mais avant tout, faisons le ménage dans ce que nous avons créé précédemment :
2.
TRUNCATE TABLE transac;
DROP TABLE transac_part;
Créons ensuite la nouvelle table partitionnée. Malheureusement pour nous, nous n'allons pas pouvoir garder le type énuméré pour le code pays. Comme nous l'avons vu lors de la présentation du partitionnement par listes, la version actuelle de MySQL ne permet actuellement que les listes d'entiers. Nous allons donc supposer l'existence d'une table Pays avec les enregistrements suivants :
|
Id |
code |
|
1 |
BE |
|
2 |
FR |
|
3 |
UK |
|
4 |
US |
|
5 |
CA |
|
6 |
JP |
Voyons maintenant le code pour créer la table de transactions partitionnée par listes de pays :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
CREATE TABLE transac_part
(
id INT UNSIGNED NOT NULL,
montant INT UNSIGNED NOT NULL,
jour DATE NOT NULL,
codePays TINYINT UNSIGNED NOT NULL
) PARTITION BY LIST(codePays)
(
PARTITION pEurope VALUES IN (1, 2, 3),
PARTITION pAmeriqueNord VALUES IN (4, 5),
PARTITION pAsie VALUES IN (6)
);
Rien de bien difficile comme vous pouvez le constater. Nous utilisons PARTITION BY LIST(x) où x est une expression de type entier, ici la valeur de la colonne codePays. Ensuite, pour chaque partition, nous définissions une liste de valeurs grâce à l'opérateur VALUES IN. Toutes les valeurs d'une liste sont séparées par une virgule.
Pour pouvoir réaliser nos tests, remplissons à nouveau nos tables. Comme tout à l'heure, j'ai choisi d'insérer 10 millions d'enregistrements.
2.
3.
4.
5.
mysql> CALL remplir_transaction(10000000);
Query OK, 1 row affected (11 min 27.53 sec)
mysql> INSERT INTO transac_part SELECT * FROM transac;
Query OK, 10000000 rows affected (1 min 31.05 sec)
Premier test de requêtes : récupérer le montant total et moyen des transactions passées dans des pays européens :
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE codePays IN ('BE', 'FR', 'UK');
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 12494719959 | 2499.8364 |
+--------------+--------------+
1 row in set (15.40 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE codePays IN (1, 2, 3);
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 12494719959 | 2499.8364 |
+--------------+--------------+
1 row in set (11.33 sec)
Un gain de 4 secondes : ce n'est pas si mal ! Si cette requête est souvent exécutée sur un serveur, notre partitionnement par listes se montre assez efficace.
Refaisons la même requête, mais pour les transactions en Asie, qui dans notre cas sont limitées au Japon.
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE codePays = 'JP';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 15268321752 | 9166.1114 |
+--------------+--------------+
1 row in set (16.53 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE codePays = 6;
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 15268321752 | 9166.1114 |
+--------------+--------------+
1 row in set (4.40 sec)
Pour cette requête, le nombre d'enregistrements à analyser est beaucoup plus petit que précédemment avec les pays européens. Notre partitionnement est donc encore plus efficace dans ce cas.
Supposons maintenant que notre entreprise se soit implantée sur le marché italien. Nous devons donc modifier notre partitionnement par listes :
2.
3.
4.
5.
INSERT INTO pays VALUES (7, 'IT');
ALTER TABLE transac_part REORGANIZE PARTITION pEurope INTO (
PARTITION pEurope VALUES IN (1, 2, 3, 7)
)
Comme vous pouvez le constater, il n'aurait pas été aussi simple de modifier le partitionnement si nous avions utilisé des intervalles. Il aurait fallu renuméroter les codes de pays pour avoir un intervalle valide de 1 à 4.
Il est impossible d'insérer une transaction réalisée en Italie (codePays = 7) en gardant la partition pEurope initiale. En effet, toute valeur de la colonne codePays doit se trouver dans une liste des partitions, sans quoi l'insertion produira une erreur. En voilà la preuve :
2.
3.
mysql> INSERT INTO transac_part VALUES (10000001, 15, '2005-11-25', 7);
ERROR 1513 (HY000): Table has no partition for value 7
II-F. Partitionnement par hachage (Hash partitioning)▲
Passons au troisième type de partitionnement horizontal proposé par MySQL : le partitionnement par hachage. Comme nous l'avons vu pour les partitionnements par intervalles et par listes, nous devons spécifier le futur emplacement de chaque enregistrement. Mais avec le partitionnement par hachage, MySQL se charge de tout à votre place ! Il suffit de spécifier le nombre de partitions désiré et le nom de la colonne qui sera hachée.
Refaisons un partitionnement par rapport à l'année de la transaction, comme nous l'avions réalisé avec un partitionnement par intervalles.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
DROP TABLE transac_part;
CREATE TABLE transac_part
(
id INT UNSIGNED NOT NULL,
montant INT UNSIGNED NOT NULL,
jour DATE NOT NULL,
codePays ENUM('FR', 'BE', 'UK', 'US', 'CA', 'JP') NOT NULL
) PARTITION BY HASH(YEAR(jour)) PARTITIONS 11;
INSERT INTO transac_part SELECT * FROM transac;
La syntaxe est beaucoup plus simple comme vous pouvez le remarquer. Mais nous allons voir si les requêtes sont toujours aussi optimisées. Exécutons donc à nouveau une des requêtes précédentes.
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE jour BETWEEN '1998-01-01' AND '1998-12-31';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 2068877605 | 2275.1570 |
+--------------+--------------+
1 row in set (17.77 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE jour BETWEEN '1998-01-01' AND '1998-12-31';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 2068877605 | 2275.1570 |
+--------------+--------------+
1 row in set (22.17 sec)
Voici un exemple d'optimisation complètement ratée ! Mais grâce à cela, nous allons pouvoir comprendre un peu mieux le partitionnement par hachage. Toute d'abord, demandons à MySQL le schéma d'exécution de notre requête en utilisant la commande EXPLAIN PARTITIONS.
2.
3.
4.
5.
6.
7.
mysql> EXPLAIN PARTITIONS SELECT SUM(montant), AVG(montant) FROM transac_part
-> WHERE jour BETWEEN '1998-01-01' AND '1998-12-31'\G
*************************** 1. row ***************************
...
partitions: p0,p1,p2,p3,p4,p5,p6,p7,p8,p9,p10
...
Les onze partitions sont scannées pour notre requête, ce qui explique le mauvais temps d'exécution. MySQL n'est donc pas capable d'optimiser notre requête comme il le faisait si bien avec un partitionnement par intervalles. De même, si nous réécrivons la clause where sous la forme YEAR(jour) = 1998, cela ne fonctionnera pas non plus.
Comme vous pouvez le comprendre, avant d'établir un partitionnement, il faut veiller à bien tester si MySQL est capable d'optimiser l'exécution de vos requêtes. Un mauvais partitionnement n'améliorera pas les performances ; pire encore, il les dégradera !
Actuellement, le seul moyen de profiter du partitionnement par hachage pour une répartition en fonction de l'année est de stocker l'année dans une colonne de type entier. Il est donc préférable dans ce cas de garder le type DATE ainsi qu'un partitionnement par intervalles.
Néanmoins, ne croyez pas que le partitionnement par hachage soit inutile avec MySQL. Avec des valeurs auto-incrémentées par exemple, ce type de partitionnement permet de répartir de manière équitable les enregistrements dans les différentes partitions. Ceci permettra dans un futur proche à MySQL de réaliser une parallélisation de requêtes pour les systèmes disposant de plusieurs CPU. Mais à l'heure actuelle, le partitionnement par hachage peut quand même se montrer intéressant. Voyons comment grâce à l'exemple suivant.
Imaginons de nouveau que les employés de notre entreprise accèdent aux données principalement en fonction de leur emplacement géographique. Nous pouvons, pour accélérer les requêtes, partitionner en fonction du pays.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
DROP TABLE transac_part;
CREATE TABLE transac_part
(
id INT UNSIGNED NOT NULL,
montant INT UNSIGNED NOT NULL,
jour DATE NOT NULL,
codePays TINYINT UNSIGNED NOT NULL
) PARTITION BY HASH(codePays) PARTITIONS 6;
INSERT INTO transac_part SELECT * FROM transac;
Avec ce code, nous avons créé 6 partitions. Si nous supposons que 6 codes pays soient valides, chaque partition contiendra les transactions d'un seul pays. S'il y a plus de 6 codes, une partition pourra contenir des transactions de pays différents.
Dans notre exemple, il y a 6 pays différents. Donc chaque partition sera utilisée et réservée pour un seul pays. Testons dès à présent une requête :
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE codePays = 1;
+--------------+--------------+
| sum(montant) | avg(montant) |
+--------------+--------------+
| 1388016754 | 833.2588 |
+--------------+--------------+
1 row in set (12.56 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE codePays = 1;
+--------------+--------------+
| sum(montant) | avg(montant) |
+--------------+--------------+
| 1388016754 | 833.2588 |
+--------------+--------------+
1 row in set (4.53 sec)
Et maintenant, si nous voulons les transactions d'un continent : par exemple les codes pays 1, 2 et 3 :
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE codePays IN (1, 2, 3);
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 12504285818 | 2500.8422 |
+--------------+--------------+
1 row in set (21.36 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE codePays IN (1, 2, 3);
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 12504285818 | 2500.8422 |
+--------------+--------------+
1 row in set (13.78 sec)
Si vous aviez des doutes quant à l'efficacité du partitionnement par hachage, j'espère vous avoir convaincu. Pourtant notre table ne comporte « que » 10 millions d'enregistrements. Bon nombre d'entreprises ont des bases de données bien plus grandes que cela !
II-G. Partitionnement par clé (Key partitioning)▲
Passons maintenant au dernier type de partitionnement horizontal. Nous n'allons pas nous attarder dessus. Le partitionnement par clé est entièrement similaire au partitionnement par hachage, à la seule différence que la fonction de hachage est fournie par le serveur MySQL. Celle-ci est généralement basée sur l'algorithme de la fonction PASSWORD(), sauf dans le cas de MySQL Cluster, où la fonction de hachage est MD5().
Pour mettre en place un partitionnement par clé, il suffit de le spécifier grâce à PARTITION BY KEY(x) où x contient un ou plusieurs noms de colonnes. Les colonnes utilisées pour le partitionnement doivent toutes faire partie de la clé primaire, si la table en possède une. De plus si aucun nom de colonne n'est spécifié, toute la clé primaire sera utilisée pour le partitionnement.
Tout comme pour le partitionnement par hachage, le nombre de partitions désiré est spécifié grâce à PARTITIONS nb. L'intérêt du partitionnement par clé est, selon moi, très limité pour l'instant, mais sera fort intéressant lorsque la parallélisation des requêtes sera permise par MySQL.
Par exemple, si nous voulons répartir 10 millions de transactions dans 5 partitions, le code suivant peut être utilisé :
2.
3.
4.
5.
6.
7.
CREATE TABLE transac_part
(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
montant INT UNSIGNED NOT NULL,
jour DATE NOT NULL,
codePays ENUM('FR', 'BE', 'UK', 'US', 'CA', 'JP') NOT NULL
) PARTITION BY KEY() PARTITIONS 5;
Aucun paramètre n'est spécifié à KEY(). Ainsi, MySQL fera le partitionnement en utilisant toutes les colonnes de la clé primaire. Ici, seul le champ id sera pris en compte et notre code serait équivalent si nous écrivions PARTITION BY KEY(id).
Comme l'identifiant est en AUTO_INCREMENT, MySQL se chargera de répartir équitablement les nouvelles insertions dans des partitions différentes. Ainsi, si nous insérons 10 millions de transactions, chaque partition en contiendra exactement 2 millions.
Nous n'allons pas réaliser de tests de requêtes sur cette table. Cela serait complètement inutile : l'index de la clé primaire nous permet déjà un accès très rapide sans partitionnement. Par contre, il serait intéressant de réaliser quelques tests quand la parallélisation de requêtes sera possible. Personnellement, je ne disposerai sûrement pas du matériel nécessaire pour ces tests, je compte donc sur vous :-)
II-H. Sous-partitionnement (Subpartitioning)▲
Jusqu'à présent, nous nous sommes limités au partitionnement simple, sur un seul niveau. Mais bien sûr, rien n'empêche de partitionner des partitions ! Ce partitionnement sur plusieurs niveaux est appelé partitionnement composite, ou encore sous-partitionnement. Avec MySQL, il est possible de faire un partitionnement composite, mais seulement sur 2 niveaux. De plus, le partitionnement de second niveau ne peut être qu'un partitionnement par clé ou par hachage.
Retournons à nos transactions et imaginons maintenant que les requêtes fréquentes se fassent en fonction de la date (année) et de l'emplacement géographique (continent). En d'autres termes, il s'agit des exemples précédents combinés en un seul.
Une solution de partitionnement serait de répartir les transactions selon leur date (partitionnement par intervalles) puis selon leur emplacement géographique (partitionnement par listes). Malheureusement, cela n'est pas possible avec MySQL 5.1 puisque le partitionnement du deuxième niveau ne peut être que par clé ou par hachage.
En tenant compte de cette contrainte un peu gênante, nous allons mettre en place un partitionnement par intervalles pour les dates qui sera lui-même partitionné par hachage pour les pays. Voici le code qui permet de faire ce sous-partitionnement :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
DROP TABLE transac_part;
CREATE TABLE transac_part
(
id INT UNSIGNED NOT NULL,
montant INT UNSIGNED NOT NULL,
jour DATE NOT NULL,
codePays INT UNSIGNED NOT NULL
)
PARTITION BY RANGE(YEAR(jour))
SUBPARTITION BY HASH(codePays) SUBPARTITIONS 6
(
PARTITION p1 VALUES LESS THAN(1997),
PARTITION p2 VALUES LESS THAN(1998),
PARTITION p3 VALUES LESS THAN(1999),
PARTITION p4 VALUES LESS THAN(2000),
PARTITION p5 VALUES LESS THAN(2001),
PARTITION p6 VALUES LESS THAN(2002),
PARTITION p7 VALUES LESS THAN(2003),
PARTITION p8 VALUES LESS THAN(2004),
PARTITION p9 VALUES LESS THAN(2005),
PARTITION p10 VALUES LESS THAN(2006),
PARTITION p11 VALUES LESS THAN MAXVALUE
);
INSERT INTO transac_part SELECT * FROM transac;
Exécutons maintenant une requête qui concerne l'année, mais aussi l'emplacement géographique des transactions :
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac WHERE codePays=2 AND jour BETWEEN '2000-01-01' AND '2000-12-01';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 567261305 | 4058.0115 |
+--------------+--------------+
1 row in set (11.95 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part WHERE codePays=2 AND jour BETWEEN '2000-01-01' AND '2000-12-01';
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 567261305 | 4058.0115 |
+--------------+--------------+
1 row in set (0.88 sec)
Et voilà le travail ! Une optimisation très impressionnante. Cela prouve que le sous-partitionnement est certes un peu plus complexe à mettre en place, mais s'il est adapté aux requêtes fréquentes, le gain est énorme. C'est avec le sous-partitionnement que vous pourrez obtenir les meilleurs résultats d'optimisation. Il est donc conseillé de le maîtriser au mieux.
Le nombre de sous-partitions étant élevé (66 = 11 * 6), il se peut que les performances de requêtes ayant besoin d'accéder à tous les enregistrements soient ralenties. Faisons donc un petit test :
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac;
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 49998688174 | 4999.8688 |
+--------------+--------------+
1 row in set (20.23 sec)
2.
3.
4.
5.
6.
7.
8.
9.
mysql> SELECT SUM(montant), AVG(montant) FROM transac_part;
+--------------+--------------+
| SUM(montant) | AVG(montant) |
+--------------+--------------+
| 49998688174 | 4999.8688 |
+--------------+--------------+
1 row in set (34.20 sec)
Comme nous pouvions nous en douter, ce nombre important de partitions dégrade significativement les performances de requêtes générales (sans clause WHERE par exemple). Bien sûr, si vous optez pour un partitionnement, ces requêtes doivent être rarement exécutées sans quoi vous ne feriez qu'alourdir le temps d'occupation du serveur !
Avant d'en terminer avec le sous-partitionnement, notons que MySQL permet de stocker chaque sous-partition sur un disque différent. Cette fonctionnalité sera sûrement très utile aux personnes manquant d'espace disque. L'exemple suivant montre comment utiliser ce stockage réparti, aussi bien pour les données que pour les index des sous-partitions.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
CREATE TABLE transac
(
-- Définition des colonnes de la table
)
PARTITION BY RANGE(YEAR(jour))
SUBPARTITION BY HASH(codePays)
(
PARTITION p0 VALUES LESS THAN (1997) (
SUBPARTITION s0
DATA DIRECTORY = '/disk0/data'
INDEX DIRECTORY = '/disk0/idx',
SUBPARTITION s1
DATA DIRECTORY = '/disk1/data'
INDEX DIRECTORY = '/disk1/idx',
...
),
PARTITION p1 VALUES LESS THAN (1998) (
SUBPARTITION s0
DATA DIRECTORY = '/disk2/data'
INDEX DIRECTORY = '/disk2/idx',
SUBPARTITION s1
DATA DIRECTORY = '/disk3/data'
INDEX DIRECTORY = '/disk3/idx',
...
),
...
);
II-I. Synthèse des commandes importantes▲
Voici une synthèse des principales commandes de MySQL pour gérer un partitionnement horizontal. Pour plus de détails, consultez la documentation officielle.
-
Créer une table partitionnée par intervalles ou par listes
Sélectionnez1.
2.
3.
4.
5.
6.
7.
8.
9.CREATETABLEnom_table(-- Définition des colonnes de la table)PARTITIONBY{RANGE(expr)|LIST(expr)}(PARTITIONnom_part1VALUES{LESSTHAN(expr)|IN(liste_valeurs)}, ...) -
Créer une table partitionnée par clé ou par hachage
Sélectionnez1.
2.
3.
4.
5.
6.CREATETABLEnom_table(-- Définition des colonnes de la table)PARTITIONBY{KEY(liste_colonnes)|HASH(expr)}PARTITIONSnb_partitions -
Créer une table sous-partitionnée
Sélectionnez1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.CREATETABLEnom_table(-- Définition des colonnes de la table)PARTITIONBY{RANGE(expr)|LIST(expr)}SUBPARTITIONBY{KEY(liste_colonnes)|HASH(expr)}SUBPARTITIONSnb_sous-partitions_par_partition(PARTITIONnom_part1VALUES{LESSTHAN(expr)|IN(liste_valeurs)}, ...) -
Supprimer une ou plusieurs partitions d'un partitionnement par intervalles ou listes : les données sont perdues !
Sélectionnez1.ALTERTABLEnom_tableDROPPARTITION(nom_part1, nom_part2, ...) -
Ajouter une partition à un partitionnement par intervalles ou listes
Sélectionnez1.ALTERTABLEnom_tableADDPARTITION(PARTITIONnom_partVALUES...) -
Fusionner deux partitions d'un partitionnement par intervalles ou listes
Sélectionnez1.
2.ALTERTABLEnom_tableREORGANIZEPARTITION(nom_part1, nom_part2)INTO(PARTITIONnom_partVALUES...) -
Exploser une partition en deux pour un partitionnement par intervalles ou listes
Sélectionnez1.
2.ALTERTABLEnom_tableREORGANIZEPARTITION(nom_part)INTO(PARTITIONnom_part1VALUES...,PARTITIONnom_part2VALUES...) -
Réparer, optimiser, vérifier, analyser une ou plusieurs partitions
Sélectionnez1.
2.
3.
4.ALTERTABLEnom_tableOPTIMIZEPARTITION(nom_part1, nom_part2, ...);ALTERTABLEnom_tableCHECKPARTITION(nom_part1, ...);ALTERTABLEnom_tableANALYZEPARTITION(nom_part1, ...);ALTERTABLEnom_tableREPAIRPARTITION(nom_part1, ...); - Redéfinir le schéma de partitionnement d'une table
2.
ALTER TABLE nom_table PARTITION BY { HASH(expr) | KEY(cols) | LIST(expr) | RANGE(expr)
-- Définition de partitions (voir création de tables partitionnées)
II-J. Nombre d'enregistrements minimum▲
Jusqu'à présent, nous avons vu comment et pourquoi utiliser le partitionnement horizontal. Mais nous n'avons pas défini la taille minimale d'une table pour avoir besoin du partitionnement. C'est assez difficile de le faire. Vous avez remarqué que pour les tests, j'utilisais 10 millions d'enregistrements. Les gains étaient quand même significatifs, même si la table était relativement petite puisque chaque enregistrement faisait moins de 20 octets dans la base.
Dans certains cas, le partitionnement horizontal sera sûrement très apprécié pour 500 000 enregistrements. Tout ce que je peux vous conseiller, c'est de faire des tests. Comme vous l'avez vu, il est très rapide de faire une copie d'une table et de la partitionner.
Ceci dit, je doute fortement que le partitionnement horizontal soit très utile aux webmasters amateurs. À moins que le trafic soit vraiment élevé !
II-K. Et les index dans tout ça ?▲
Le partitionnement ne remplace bien sûr pas l'utilisation des index. Au contraire, ces deux techniques sont très complémentaires pour optimiser au mieux les requêtes. Des exemples mettant en œuvre index et partitionnement seront bientôt disponibles dans ce document.
Pour l'instant, tout s'est déroulé pour le mieux puisque nous avons réussi à optimiser plusieurs types de requêtes. Néanmoins, tout au long des tests, nous avons été confrontés à des limitations de MySQL. Même si des substituts ont pu être trouvés simplement, il est nécessaire de faire le point sur les possibilités offertes par MySQL 5.1.
Voici une liste non exhaustive des limitations actuelles (MySQL 5.1.11 bêta) :
- difficulté d'utiliser des index : UNIQUE et PRIMARY KEY ne peuvent être utilisés que si toutes les colonnes concernées par le partitionnement font partie de l'index. Il n'est donc pas possible d'avoir une colonne d'identifiant numérique en clé primaire, à moins que le partitionnement soit réalisé à partir de cet identifiant. Selon le responsable du partitionnement chez MySQL AB, cette limitation sera fixée dès que les index globaux seront gérés, ce qui ne devrait pas trop tarder ;
-
l'optimiseur est peu intelligent. Pour un partitionnement par intervalles ou listes sur l'année d'un champ de type DATE, il faut utiliser un intervalle de dates pour la clause where.
- méthode optimisée : WHERE jour BETWEEN 'YYYY-MM-DD' AND 'YYYY-MM-DD'
- méthode optimisée : WHERE jour <= 'YYYY-MM-DD' AND jour >= 'YYYY-MM-DD'
- méthode NON optimisée : WHERE YEAR(jour) = 2005
Pensez à utiliser EXPLAIN PARTITIONS quand vous mettez en place un partitionnement. Vous pourrez ainsi savoir si vos requêtes sont exprimées de façon à être optimisées ;
- le partitionnement par listes n'accepte que des entiers. Il n'est donc malheureusement pas possible de créer des listes de chaînes. De plus, on regrettera que les types énumérés ne soient pas gérés pour ce type de partitionnement, même après un CAST() ;
- le sous-partitionnement ne peut se faire qu'avec des listes ou des intervalles pour le premier niveau, et avec un hachage ou une clé sur le second niveau. Il est donc impossible de mélanger listes et intervalles ;
- la parallélisation des requêtes n'est pas encore possible. Le partitionnement prendra tout son sens quand cette fonctionnalité sera disponible ;
- les tables partitionnées ne supportent pas les clés étrangères et les index FULLTEXT.
Malgré ces limitations, qui seront probablement vite comblées, j'espère que vous avez pu apprécier autant que moi ces nouvelles fonctionnalités. Il est évident qu'il reste beaucoup de travail pour les développeurs de MySQL AB, mais tout cela est de bon augure pour le futur de leur SGBD.
III. Le partitionnement vertical avec MySQL▲
Nous venons de voir comment optimiser nos requêtes grâce à un partitionnement horizontal. En gardant à l'esprit que plus les tables sont petites, plus les requêtes s'exécutent rapidement, nous pouvons en déduire qu'il est également possible d'optimiser nos requêtes grâce à un partitionnement vertical.
Malheureusement, MySQL 5.1 ne gère pas automatiquement le partitionnement vertical, comme il le fait pour l'horizontal. De plus, cette fonctionnalité n'est apparemment pas à l'ordre du jour des développeurs de MySQL AB.
Peu importe, nous pouvons nous-mêmes simuler des partitions à partir de tables et pour les gérer au mieux, nous allons utiliser deux fonctionnalités apparues dans MySQL 5 : les vues et les procédures stockées.
Afin de nous assurer que le gain de performances est bien au rendez-vous avec le partitionnement vertical, nous allons prendre l'exemple (très simplifié) d'un site de e-commerce qui possède une table de produits où celle-ci contient, pour chaque produit, différentes données ainsi qu'une photo. Pour tenter d'optimiser nos requêtes, nous allons placer les champs des photos, accédés moins fréquemment, dans une partition séparée des autres données.
Voici le code de la table Produit sans partitionnement :
2.
3.
4.
5.
6.
7.
CREATE TABLE produit
(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
libelle VARCHAR(50) NOT NULL,
prix DECIMAL(10,2) NOT NULL,
photo BLOB NOT NULL
);
Pour le champ photo, nous utilisons le type BLOB qui permet de stocker jusqu'à 64 Ko de données binaires.
Comme prévu, nous allons séparer les photos. Pour cela, nous créons une nouvelle table Photo_Produit qui contiendra, en plus des photos, l'identifiant de chaque produit pour pouvoir relier les photos à leur produit.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
CREATE TABLE produit2
(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
libelle VARCHAR(50) NOT NULL,
prix DECIMAL(10,2) NOT NULL
);
CREATE TABLE photo_produit
(
idProd INT UNIQUE NOT NULL,
photo BLOB NOT NULL
);
Nos tables de tests sont maintenant créées. Il ne nous manque plus qu'un jeu d'essai volumineux. La procédure suivante va nous permettre de remplir les tables des produits et des photos. Nous n'allons pas stocker de vraies photos : une chaîne de 20 Ko fera l'affaire.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
DELIMITER //
CREATE PROCEDURE remplir_produit(nbProds INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE _prix DECIMAL(10,2);
DECLARE _photo BLOB DEFAULT REPEAT('A', 20480);
WHILE i <= nbProds DO
SET _prix = CAST((RAND() * 1000) AS DECIMAL(10,2));
INSERT INTO produit VALUES (i, CONCAT('Produit_', i), _prix, _photo);
INSERT INTO produit2 VALUES (i, CONCAT('Produit_', i), _prix);
INSERT INTO photo_produit VALUES (i, _photo);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
Remplissons maintenant nos tables avec 10 000 produits, ce qui nous fera environ 200 Mo de photos :
2.
mysql> CALL remplir_produit(10000);
Query OK, 1 row affected (1 min 58.87 sec)
Testons dès à présent une requête simple : identifiant, libellé et prix de tous les produits.
2.
3.
mysql > SELECT id, libelle, prix FROM produit;
10000 rows in set (1 min 8.92 sec)
2.
3.
mysql> SELECT id, libelle, prix FROM produit2;
10000 rows in set (0.66 sec)
Le gain de performance est impressionnant. Bien évidemment, une requête qui récupère les informations de tous les produits est plutôt rare sur les sites de e-commerce. L'affichage des listes de produits étant souvent limité à quelques dizaines de produits dans des rubriques, le gain de performance serait bien moindre. Cependant, ceci n'est qu'un exemple pour vous montrer l'avantage du partitionnement. Dans la réalité, les requêtes d'un site de e-commerce sont beaucoup plus complexes (avec critères de recherche par exemple). Et pour les sites très fréquentés, même un gain de 0,10 seconde par requête peut être bon à prendre !
Jusqu'ici, nous avons vu que le partitionnement vertical, réalisé en séparant les champs volumineux et peu accédés, se montre efficace pour les performances. Néanmoins, nous disposons maintenant de deux tables au lieu d'une. Ceci rend l'écriture de certaines requêtes plus longue et difficile.
Pour insérer un nouveau produit, il faut donc faire deux requêtes d'insertion. Ce n'est pas bien grave, mais dans le cas d'un partitionnement vertical en 10 tables, cela peut gêner. Grâce à une procédure stockée, il est très simple de simplifier l'écriture des requêtes, comme le montre l'exemple ci-dessous :
2.
3.
4.
5.
6.
7.
8.
9.
DELIMITER //
CREATE PROCEDURE inserer_produit(_lib VARCHAR(50), _prix DECIMAL(10,2), _photo BLOB)
BEGIN
INSERT INTO produit(libelle, produit) VALUES (_lib, _prix);
INSERT INTO photo_produit VALUES (LAST_INSERT_ID(), _photo);
END //
DELIMITER ;
En appelant cette procédure, il est très facile d'insérer un nouveau produit. Le lien entre la table Produit et la table Photo_Produit est réalisé automatiquement grâce à la fonction LAST_INSERT_ID().
Le même principe peut s'appliquer pour supprimer un produit, où la procédure supprimerait les lignes dans chaque table concernée par le partitionnement.
De plus, pour faciliter l'écriture de vos SELECT qui concernent toutes les données de produits, une vue peut être très utile. Grâce à celle-ci, vous pourrez exprimer vos requêtes comme si une seule table était présente. Voici la vue qui permettrait de le faire dans notre exemple :
2.
CREATE VIEW produit_complet AS
SELECT * FROM produit2 p INNER JOIN photo_produit ph ON p.id = ph.idProd;
Après la création de cette vue, il est donc possible d'exécuter des requêtes telles que :
2.
3.
SELECT * FROM produit_complet WHERE id = 5;
SELECT * FROM produit_complet WHERE prix < 100;
L'exécution de ces requêtes avec notre partitionnement est certes un peu plus longue que si toutes les données n'étaient pas séparées dans deux tables, puisqu'une jointure doit être réalisée. Cependant, les jointures SQL étant très optimisées dans les SGBD, cette perte de performances est très minime. Et rappelons que si le partitionnement est bien réalisé, ces requêtes ralenties seront beaucoup plus rares que celles que nous avons optimisées !
IV. Nettoyage▲
Si vous avez réalisé les différents tests proposés dans l'article, n'oubliez pas de nettoyer votre base de données, car dans le cas contraire, vous perdriez presque 500 Mo d'espace disque ! Le script suivant efface tout ce qui a pu être créé en reproduisant les exemples :
2.
3.
4.
5.
DROP TABLE transac, transac_part, produit, produit2, photo_produit;
DROP PROCEDURE remplir_transaction, remplir_produit, inserer_produit;
DROP VIEW produit_complet;
V. Conclusion▲
Dans cet article, nous avons d'abord découvert les deux méthodes de partitionnement :
- le partitionnement horizontal qui consiste à répartir les enregistrements (= les lignes) ;
- le partitionnement vertical qui consiste à répartir les attributs (= les colonnes).
Ensuite, nous avons vu comment utiliser le partitionnement horizontal avec MySQL dans différentes situations. Cinq types de partitionnements horizontaux ont été présentés : par intervalles, par listes, par hachage, par clé et le sous-partitionnement.
Grâce au partitionnement horizontal, il est possible d'optimiser des requêtes et cela très simplement puisque MySQL organise automatiquement les données réparties. Malheureusement, le support du partitionnement étant encore à ses débuts dans MySQL, de nombreuses limitations existent comme nous avons pu le remarquer.
Après cela, nous avons mis en œuvre un partitionnement vertical, qui n'est pas géré automatiquement par MySQL. Le partitionnement vertical ajoute du travail et rend plus difficile l'expression de certaines requêtes. Mais comme nous l'avons vu, tout cela en vaut la peine. Le but recherché est de séparer les données volumineuses rarement accédées, des autres données fréquemment utilisées.
J'espère que ce tutoriel vous aura permis de prendre conscience de l'importance du partitionnement ainsi que sa simplicité de mise en place avec MySQL 5.1. Je reste bien sûr à votre disposition pour toute question (non technique, pour cela il y a le forum) ou remarque. Vous pouvez me contacter par ou par message privé.
VI. Ressources▲
Si vous voulez en savoir plus sur l'utilisation du partitionnement avec MySQL, je vous conseille ces ressources :
- le chapitre 18 de la documentation officielle de MySQL 5.1 : partitioning
http://dev.mysql.com/doc/refman/5.1/en/partitioning.html;
- le blog de Mikael Ronstrom, le responsable du partitionnement chez MySQL
http://mikaelronstrom.blogspot.com;
- le forum officiel consacré au partitionnement
VII. Remerciements▲
Nous tenons à remercier plusieurs personnes, sans qui cet article n'aurait jamais vu le jour :
Kamel Chelghoum, professeur de bases de données à l'Université de Metz, qui m'a fait connaître le partitionnement.
Maximilian, responsable MySQL sur developpez.com, pour ses conseils et la relecture de l'article.
David Burgermeister, rédacteur sur developpez.com, pour sa relecture et ses suggestions.
Alexandre Tranchant, rédacteur sur developpez.com, pour son très bon article sur le programmateur d'événements de MySQL5.1 qui m'a donné envie de m'intéresser aux nouveautés de MySQL.
Nous tenons à remercier Claude Leloup pour sa relecture orthographique et Malick Seck pour la mise au gabarit.